Dimensional Affect: an Explainer of Valence, Arousal, and Dominance (VAD)

Image created partially with Bing using Dall-E3
Have you ever asked yourself, why do humans spend such an enormous amount of time and energy on faces? Taking pictures, using make-up, and writing elaborate descriptions in books and stories?
The answer is that the face is probably the most used and most versatile interactive interface you will ever encounter. It is not an exaggeration to say that the face is your main means of interaction with the world around you, both in terms of sensing and in terms of signalling. The face is our most important mode of non-verbal communication, with a wealth of communicative signals coming from its facial displays, head movements and gaze directions (emotion expert Gary McKeown calls it the organ of human communication). It is therefore only natural that humans have been studying facial expressions with written notes dating back to the ancient Greeks, and possibly even before that. Some of this signalling is done consciously, some unconsciously. Some of the states that cause the signals are transient, such as emotion, others are permanent, such as identity. Interpreting the facial signals of emotion, be it displayed consciously or unconsciously, is one of the things that BLUESKEYE AI excels at.
This does raise the question, what is emotion? How do we interpret these facial signals in terms of a well defined set of variables laid out by emotion theory?
Unfortunately, philosophers, psychologists, neuroscientists and computer scientists have to date not come to an agreement on how to define emotion. A number of competing theories exist, none of them perfect, but some are more useful than others. The theory used by BLUESKEYE AI and in our opinion the most useful of all is the Dimensional Affect Model, alternatively known as the valence and arousal or VAD model.
So what is this valence and arousal then?
The valence, arousal and dominance model was originally proposed by Albert Mehrabian and James Russell as a 2-dimensional circumplex model of valence and arousal, with dominance added later. It is the most common dimensional affect model. It describes every emotion as a point in a two-dimensional space, with the horizontal axis being Valence - how positive or negative you are feeling, and the vertical axis being arousal - how much energy you have, or sometimes interpreted as the intensity of the felt emotion. Arousal has therefore nothing to do with any feelings of sensual desire. Dominance describes how much a person feels in control of the situation. It is crucial to distinguish between emotions such as anger and fear, which largely overlap in the valence-arousal plane. Anger would have a high dominance value though, and fear a low dominance value. Low dominance is not always bad though - thrill seekers abandon control on purpose to seek enjoyment or to subject themselves to new experiences, such as the enjoyment of exciting theme park rides.
You can think of dimensional affect as music - where positive valence is like a happy, uplifting note, and negative valence is sad or somber note. The intensity of these emotions can be described by the level of volume (arousal). Positive dominance means you are directing the music, negative dominance means you’re in the audience just absorbing it all.

Figure 1. Dimensional affect space with valence on the horizontal and arousal on the vertical axis. A number of emotion categories are drawn in the space.
You may have heard of the theory of six (sometimes seven) basic emotions proposed by Paul Ekman and popularised by things like the Disney film ‘Inside Out’. The six basic emotions are Anger, Disgust, Fear, Happiness, Sadness, and Surprise, and were posited to be universally recognised and displayed the same by anyone regardless of culture or upbringing. This model has come under a lot of fire recently, and in particular, its discrete nature is problematic for practical use. People can feel and express far more emotions than those six. Just look at the many ways writers and poets describe emotion.
The beauty of the dimensional affect model is that it allows for subtle differences in the intensity of emotion, it shows transitions between states over time clearly in a 3-dimensional space, allows much more granular differences between emotion categories.
What’s in it for me? What’s the benefit for the customers of my products?
Blueskeye’s measurement of continuous emotion has three main benefits. It allows you as a product or experience designer to define emotionally where your customer is, where you want that person to be and how well you are doing in reaching that destination.
BLUESKEYE AI makes it possible to estimate apparent valence and arousal from the face and voice, without requiring the user to complete task-disrupting questionnaires. If you apply this in the automotive setting, you can now let a user indicate what mood they want to be in (their goldilocks zone) and adjust the cabin environment to get them to their desired state. The product we created for the automotive market is called B-Automotive and it can tell you what apparent emotion the car’s occupants are in, and if your efforts to get them into their desired state are actually working (see image below).
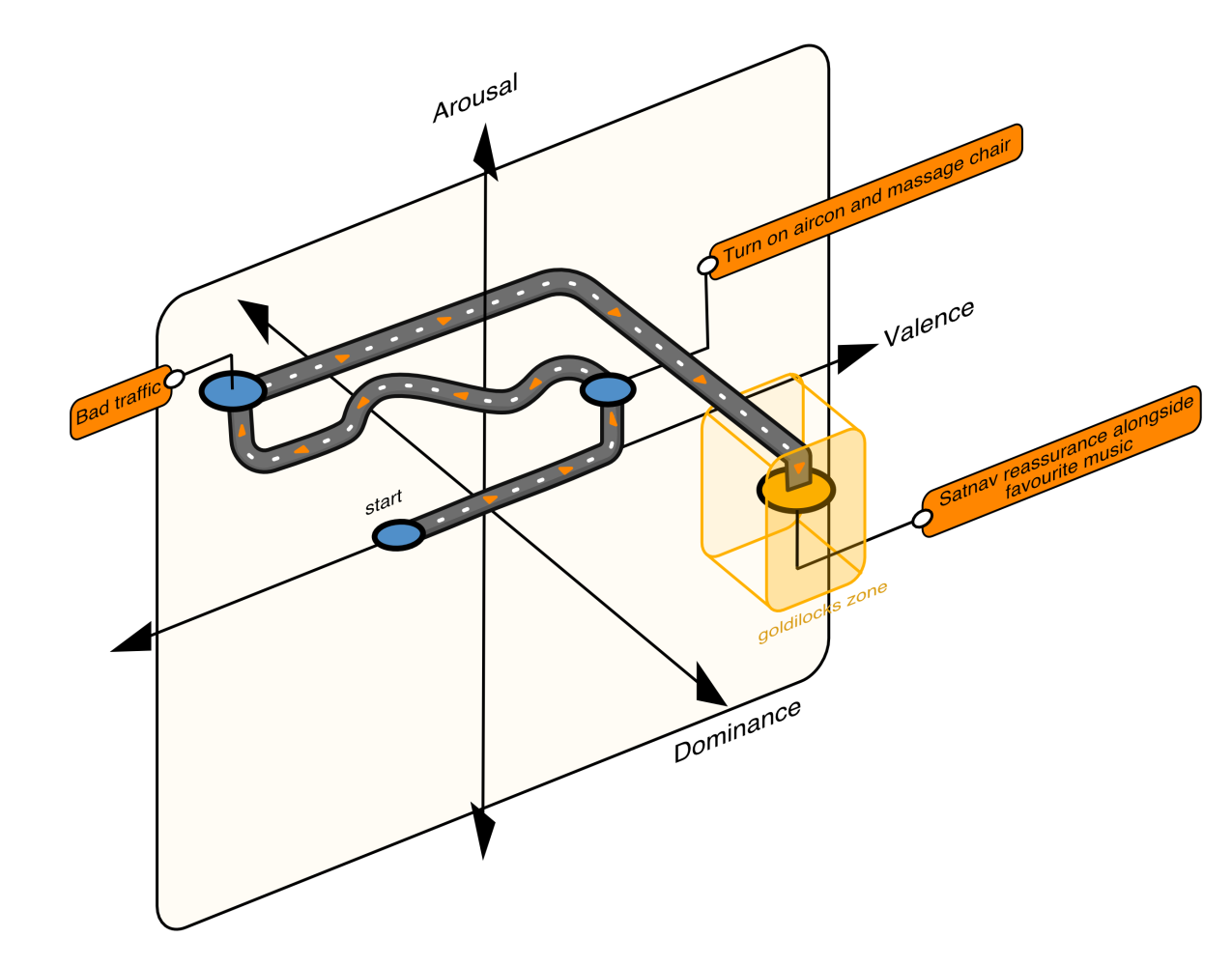
Figure 2. A journey through the VA space from initial emotional state to the goldilocks zone, with external and internal events affecting the car occupant’s emotion.
Another use case in the automotive industry is to use the apparent emotion as a real-time, repeatable and objective measure in user experience and user interaction studies. A lot of time and effort goes into designing the interior of a car, and the way a driver controls the car. Getting feedback about what they enjoy, hate, or find confusing is super powerful, especially when combined with BLUESKEYE’s gaze tracking. And this technology is not just for testing in the lab, it can also be used to measure user experience after a car has been launched on the market, for example, to test over-the-air updates of user interface features.
In the health space, apparent emotion can be used to measure the interest in and confusion with companion apps and any health information material that you produce. Increasing adherence to treatment is important, and knowing when you’re losing a patient’s interest and comprehension is possible using valence and arousal predictions. BLUESKEYE AI has created the Health Foundation Platform that allows you to test this and other indicators of medically relevant behaviour during your clinical trials.
In social robotics, which can include virtual assistants and intelligent kiosks, knowing a person’s emotion can allow the social robot to be empathetic, and to make the robot more responsive, simplifying and improving the customer's interaction with the AI system. Your users will get a better experience and user retention will go up! BLUESKEYE has a dedicated SDK for social robots, called B-Social.
So. How would YOU use automatic dimensional affect recognition?
Acknowledgments
Many thanks to Dr Gary McKeown of Queen’s University Belfast, long-standing collaborator and great expert on dimensional affect for reviewing this article! Thank you for the human organ quote. I now visualise a face shaped like a set of windpipes.
More! I want to learn more!
I wrote a draft section on valence and arousal for a book that was never completed. Below is a more technical description for those who want to learn the nitty gritty .
The circumplex of affect, proposed by James Russell, is the most common dimensional affect model. Named after the circular two-dimensional space that was used initially, it represents the affective state of a subject through two continuous-valued variables indicating arousal (ranging from relaxed to aroused) and valence (from pleasant to unpleasant). It is conjectured that each basic emotion corresponds to specific ranges of values within the circumplex of affect, while other emotions can be equally mapped into this representation. Dimensions other than valence and arousal can also be considered, augmenting the representational power of the model. Some of the extra dimensions most commonly used include power, dominance and expectation. Computational Face Analysis approaches using dimensional affect aim to automatically estimate a continuous value for each of the dimensions considered, most commonly on a frame-by-frame basis. The predictions are thus both continuous in time and in value.
One particular concern with applying computational face analysis to message- based emotion theories is the collection of ground-truth information of the emotion of interest for a given video. Ekman’s basic emotion theory effectively sidesteps this issue by asserting that the emotion felt is equal to the facial dis- play shown. Essentially, it states that there is no latent emotion variable. For dimensional affect approaches this is not the case. Instead, there are two ways of collecting ground-truth data of valence, arousal, and other affective dimensions; you can either ask people to self-report how they feel, or you can get observers to rate how they think the person feels. While it may seem a simple choice to go straight for self-reported emotion, this is actually difficult to do in practice. The act of reporting the emotion interrupts whatever the user is doing, which interferes with task performance and makes the interaction less real. In addition, this can only be done periodically, not continuously. Doing it after the fact is also problematic, as people’s memory of what they felt in the past has been shown to be highly inaccurate. Unfortunately, the alternative, asking observers to rate what they think someone’s emotion is, is not perfect either. Funnily enough, it turns out people actually cannot read your mind, and their interpretation of why you behave in a certain way is inaccurate. This relationship between encoder behaviour (the person expressing) and decoder judgment (the observer watching the expression) was pointed out by the psychologist Robert Rosenthal in 2005. This is also elegantly captured by the Brunswik Lens Model of the expression and perception of emotion. The model should be read as that the same felt emotion can be mapped to multiple facial displays depending on the external models pull and internal changes push on the encoder side, and on the decoder side multiple different facial displays can be mapped to the same perceived emotion depending on the currently active inference rules and schematic recognition. In addition, the distal cue transmission channel will be noisy due to e.g. bad lighting or an otherwise noisy environment.
Yet there is nothing new or unsound about distinguishing between objective reality and subjective representations of it, and both can be important. This view was established by 17th century philosophers (notably Locke). From the early 19th century, research in this area addressed topics like colour and the mathematical relationship between objective and perceived brightness, weight, etc. Ultimately, what matters for Computational Face Analysis is that humans operate as observers on a daily basis and do so effectively; being able to mimic this ability with AI is a goal worth pursuing.
Dimensional affect is normally rated in real-time, meaning that someone watches the expressive material and the observer uses a mouse, joystick, or other device to indicate the value of the affective dimension. The resulting continuous-value time- series annotations are called ‘traces’. For dimensional affect, the encoder/decoder ambiguity observed by Rosenthal is reflected in the large variance of these traces. This variation in the ratings of observers is due to a number of things. The most important problem is the differences in the interpretation of the observed facial display due as explained by the Brunswik lens model. Where one person feels they observed a wry smile, produced to hide their real intention, someone else may interpret it as a genuine smile. The resulting values for the valence dimension would be much lower for the former than the latter. Such differences in interpretation could be down to personal experience, but some of this may well be attributed to cultural differences too. The problem is that of course both observers are right. In addition there are issues that are particular to this type of emotion annotation: firstly it takes time for someone to view the expressive videos and decide what the underlying emotion is, and people take a different amount of time to make this decision, causing variations between people. In addition, people’s reaction time will vary depending on how tired they are, or how long they’ve been annotating. There are also practical issues about the device used, with joysticks that have force-feedback resulting in more reliable (as in, repeatable) annotations between annotators. Given all the evidence of the encoder-decoder ambiguity, it is disconcerting that people still talk as if traces should be understood as more or less accurate measures of an objective “ground truth” (presumably the person’s true emotion), as pointed out by Roddy Cowie and his colleagues. In conclusion, how to reconcile the dif- ferences between annotation values is a wide-open area of research in affective computing, as is the question of what underlies the differences in interpretation in the first place. This makes this an area of research that will require substantial original thought to make serious advances.
Ultimately, what matters for Computational Face Analysis is that humans operate as observers on a daily basis and do so effectively; being able to mimic this ability with AI is a goal worth pursuing.
Written by BlueSkeye Founding, CESO, Prof Michel Valstar
See original post on LinkedIn HERE